HTTP发展史
省流总结
HTTP1.0和HTTP1.1
- HTTP1.0默认是
短连接。每次与服务器交互,都需要新开一个TCP连接;
HTTP1.1默认是长连接。只要客户端服务端没有断开TCP连接,就一直保持连接,可以发送多次HTTP请求。(目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接) - HTTP1.1支持
断点续传,只发送header信息(不带任何body信息) - HTTP1.0缓存处理:expires,HTTP1.1引入更丰富的缓存字段如:cache-control
HTTP1.1和HTTP2.0
- HTTP1.1请求头header以纯文本传输;HTTP2.0支持
头部压缩 - HTTP1.1是以
文本格式传输数据,HTTP2.0改用二进制格式传输数据 - HTTP1.1需要等上一个请求的响应数据回来后才能发送另一个请求;
HTTP2.0设计了Stream概念,多个 Stream 复用同一个TCP连接,并发处理多个请求 - HTTP2.0支持
服务端推送
HTTP/2 通过头部压缩、二进制编码、多路复用、服务器推送等新特性大幅度提升了 HTTP/1.1 的性能,而美中不足的是 HTTP/2 协议是基于 TCP 实现的,于是存在的缺陷有三个。
- TCP的队头阻塞并没有彻底解决
- TCP以及TCP+TLS建立连接的延时
- 网络迁移需要重新连接
HTTP2.0和HTTP3.0
- HTTP3.0弃用TCP,基于UDP实现了
QUIC协议,彻底解决了TCP层的队头堵塞 - 更快建立连接
- 通过连接ID,实现连接迁移;
一文总结HTTP1.0,HTTP1.1,HTTP2,HTTP3,面试强心剂
HTTP/0.9
HTTP 的最早版本诞生在 1991 年。这个最早版本和现在比起来极其简单,没有 HTTP 头,没有状态码,甚至版本号也没有,后来它的版本号才被定为 0.9 来和其他版本的 HTTP 区分。HTTP/0.9 只支持一种方法—— Get,请求只有一行。
HTTP/1.0
HTTP1.0最早在网页中使用是在1996年。随着新兴网络发展,首先在浏览器中展示的不单是 HTML 文件了,还包括了 JavaScript、CSS、图片、音频、视频等不同类型的文件。服务器不知道如文件编码、文件类型,因此直接返回数据给浏览器...为了满足传输多种类型文件的需求,HTTP1.0引入了请求头 和 响应头
HTTP/1.1
HTTP1.1在HTTP1.0上的改进
😊改进持久连接
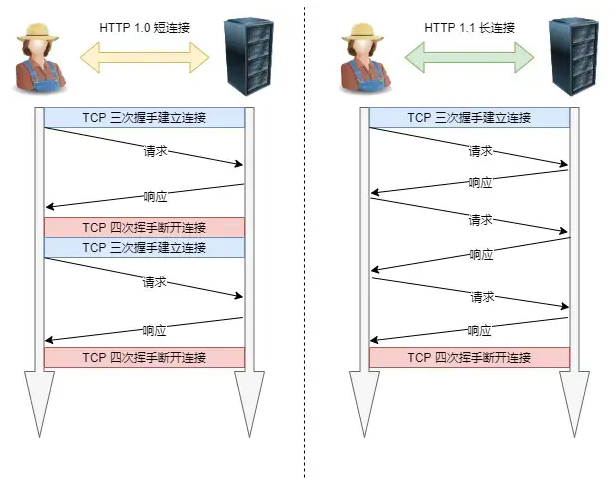
HTTP/1.0 每进行一次 HTTP 通信,都需要经历建立 TCP 连接、传输 HTTP 数据和断开 TCP 连接三个阶段。如果一个页面包含了几百个外部引用的资源文件,在下载每个文件的时候,都需要经历建立 TCP 连接、传输数据和断开连接这样的步骤,无疑会增加大量无谓的开销。
为了解决这个问题,HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
持久连接在 HTTP/1.1 中是默认开启的,所以你不需要专门为了持久连接去 HTTP 请求头设置信息,如果你不想要采用持久连接,可以在 HTTP 请求头中加上Connection: close。目前谷歌浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接。
😊不成熟的 HTTP 管线化
持久连接虽然能减少 TCP 的建立和断开次数,但是它需要等待前面的请求返回之后,才能进行下一次请求。如果 TCP 通道中的某个请求因为某些原因没有及时返回,那么就会阻塞后面的所有请求,这就是著名的队头阻塞(应用层)的问题。
HTTP/1.1 中试图通过管线化的技术来解决队头阻塞的问题。HTTP/1.1 中的管线化是指将多个 HTTP 请求整批提交给服务器的技术,虽然可以整批发送请求,不过服务器依然需要根据请求顺序来回复浏览器的请求。HTTP/1.1 管道解决了请求的队头阻塞,但是没有解决响应的队头阻塞
FireFox、Chrome 都做过管线化的试验,但是由于各种原因,它们最终都放弃了管线化技术。
😊提供虚拟主机的支持
😊对动态生成的内容提供了完美支持
😊 客户端 Cookie、安全机制
😊断点续传
要实现断点续传的功能,通常都需要客户端记录下当前的下载进度,并在需要续传的时候通知服务端本次需要下载的内容片段。
HTTP1.1协议(RFC2616)中定义了断点续传相关的HTTP头 Range和Content-Range字段,一个最简单的断点续传实现大概如下:
- 客户端下载一个1024K的文件,已经下载了其中512K
- 网络中断,客户端请求续传,因此需要在HTTP头中申明本次需要续传的片段:
Range:bytes=512000-这个头通知服务端从文件的512K位置开始传输文件 - 服务端收到断点续传请求,从文件的512K位置开始传输,并且在HTTP头中增加:
Content-Range:bytes 512000-/1024000并且此时服务端返回的HTTP状态码应该是206,而不是200。
HTTP1.1 性能瓶颈
😕请求 / 响应头部(Header)未经压缩,首部信息越多延迟越大(只能压缩 Body 的部分);
😕响应头的对头阻塞没有彻底解决;
😕没有请求优先级控制;
😕请求只能从客户端开始,服务器只能被动响应。
HTTP/2.0
HTTP2.0在HTTP1.1上的改进
😊头部压缩
HTTP 协议的报文是由「Header + Body」构成的,对于 Body 部分,HTTP/1.1 协议可以使用头字段 「Content-Encoding」指定 Body 的压缩方式,比如用 gzip 压缩,这样可以节约带宽,但报文中的另外一部分 Header,是没有针对它的优化手段。
HTTP/2 没使用常见的 gzip 压缩方式来压缩头部,而是开发了HPACK算法
😊二进制帧
HTTP/2 厉害的地方在于将 HTTP/1 的文本格式改成二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析。
😊多路复用,并发传输
知道了 HTTP/2 的帧结构后,我们再来看看它是如何实现并发传输的。
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接,达到并发的效果,解决了 HTTP/1.1 队头阻塞的问题,提高了 HTTP 传输的吞吐量。
为了理解 HTTP/2 的并发是怎样实现的,我们先来理解 HTTP/2 中的 Stream、Message、Frame 这 3 个概念。
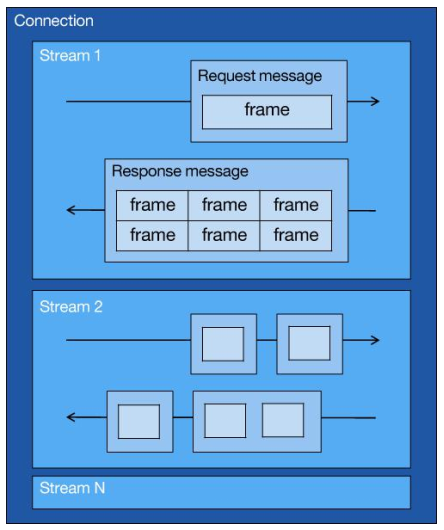
你可以从上图中看到:
- 1 个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体);
因此,我们可以得出个结论:多个 Stream 跑在一条 TCP 连接,同一个 HTTP 请求与响应是跑在同一个 Stream 中,HTTP 消息可以由多个 Frame 构成, 一个 Frame 可以由多个 TCP 报文构成。
HTTP/2 通过 Stream 实现的并发,比 HTTP/1.1 通过 TCP 连接实现并发要牛逼的多,因为当 HTTP/2 实现 100 个并发 Stream 时,只需要建立一次 TCP 连接,而 HTTP/1.1 需要建立 100 个 TCP 连接,每个 TCP 连接都要经过 TCP 握手、慢启动以及 TLS 握手过程,这些都是很耗时的。
HTTP/2 还可以对每个 Stream 设置不同优先级,帧头中的「标志位」可以设置优先级,比如客户端访问 HTML/CSS 和图片资源时,希望服务器先传递 HTML/CSS,再传图片,那么就可以通过设置 Stream 的优先级来实现,以此提高用户体验。
❓与HTTP1.1管线化的区别:
HTTP/1.1 中的管道( pipeline)虽然解决了请求的队头阻塞,但是没有解决响应的队头阻塞,因为服务端需要按顺序响应收到的请求,如果服务端处理某个请求消耗的时间比较长,那么只能等响应完这个请求后, 才能处理下一个请求,这属于 HTTP层队头阻塞。
HTTP/2 虽然通过多个请求复用一个 TCP 连接解决了 HTTP 的队头阻塞 ,但是一旦发生丢包,就会阻塞住所有的 HTTP 请求,这属于 TCP层队头阻塞。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
(使用 HTTP/1.1 时,浏览器为每个域名开启了 6 个 TCP 连接,如果其中的 1 个 TCP 连接发生了队头阻塞,那么其他的 5 个连接依然可以继续传输数据;而HTTP/2.0是一个TCP连接的,所以随着丢包率的增加,HTTP/2 的传输效率也会越来越差。有测试数据表明,当系统达到了 2% 的丢包率时,HTTP/1.1 的传输效率反而比 HTTP/2 表现得更好)
😊服务器推送
HTTP2让服务器可以将响应数据主动推送到客户端缓存中
美中不足的HTTP2.0
主要是底层的tcp协议造成的
😕TCP 的队头阻塞并没有彻底解决
因为 TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的,如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是请求被阻塞了。
😕TCP 以及 TCP+TLS 建立连接的延时
网络延迟又称为 RTT(Round Trip Time)。我们把从浏览器发送一个数据包到服务器,再从服务器返回数据包到浏览器的整个往返时间称为 RTT(如下图)。RTT 是反映网络性能的一个重要指标。
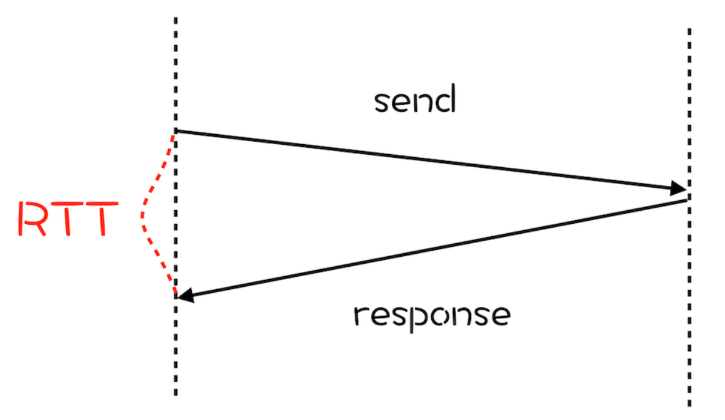
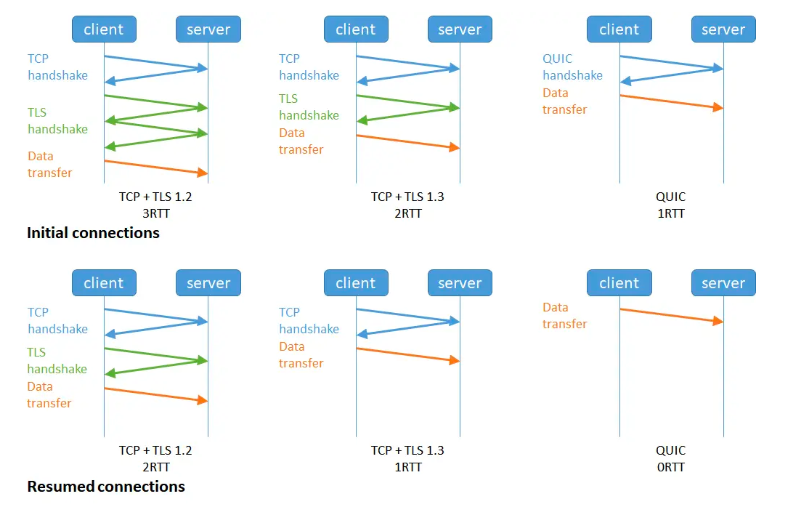
我们知道 HTTP/1 和 HTTP/2 都是使用 TCP 协议来传输的,而如果使用 HTTPS 的话,还需要使用 TLS 协议进行安全传输,而使用 TLS 也需要一个握手过程,这样就需要有两个握手延迟过程。
- 在建立 TCP 连接的时候,需要和服务器进行三次握手来确认连接成功,也就是说需要在消耗完 1.5 个 RTT 之后才能进行数据传输。
- 进行 TLS 连接,TLS 有两个版本——TLS1.2 和 TLS1.3,每个版本建立连接所花的时间不同,大致是需要 1~2 个 RTT,关于 HTTPS 我们到后面到安全模块再做详细介绍
总之,在传输数据之前,我们需要花掉 3~4 个 RTT。如果浏览器和服务器的物理距离较近,那么 1 个 RTT 的时间可能在 10 毫秒以内,也就是说总共要消耗掉 30~40 毫秒。这个时间也许用户还可以接受,但如果服务器相隔较远,那么 1 个 RTT 就可能需要 100 毫秒以上了,这种情况下整个握手过程需要 300~400 毫秒,这时用户就能明显地感受到“慢”了。
😕网络迁移需要重新连接
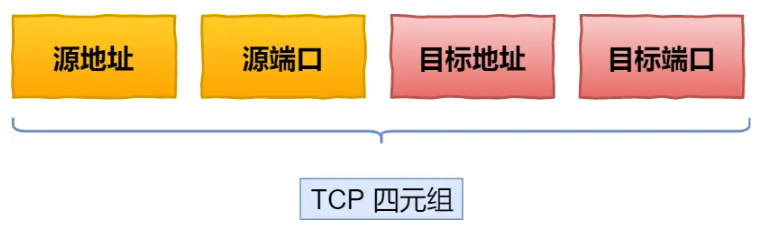
一个 TCP 连接是由四元组(源 IP 地址,源端口,目标 IP 地址,目标端口)确定的,这意味着如果 IP 地址或者端口变动了,就会导致需要 TCP 与 TLS 重新握手,这不利于移动设备切换网络的场景,比如 4G 网络环境切换成 WiFi。
HTTP/3.0
为了解决TCP协议固有的问题,HTTP/3.0把传输层协议换成了UDP!
我们深知,UDP 是一个简单、不可靠的传输协议,而且是 UDP 包之间是无序的,也没有依赖关系。
而且,UDP 是不需要连接的,也就不需要握手和挥手的过程,所以天然的就比 TCP 快。
当然,HTTP/3 不仅仅只是简单将传输协议替换成了 UDP,还基于 UDP 协议在「应用层」实现了 QUIC 协议,它具有类似 TCP 的连接管理、拥塞窗口、流量控制的网络特性,相当于将不可靠传输的 UDP 协议变成“可靠”的了,所以不用担心数据包丢失的问题。
彻底解决队头阻塞
首先了解UDP是面向报文的协议和TCP是面向字节流的协议
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
由于 QUIC 使用的传输协议是 UDP,UDP 不关心数据包的顺序,如果数据包丢失,UDP 也不关心。
不过 QUIC 协议会保证数据包的可靠性,每个数据包都有一个序号唯一标识。当某个流中的一个数据包丢失了,即使该流的其他数据包到达了,数据也无法被 HTTP/3 读取,直到 QUIC 重传丢失的报文,数据才会交给 HTTP/3。
而其他流的数据报文只要被完整接收,HTTP/3 就可以读取到数据。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
更快的连接建立
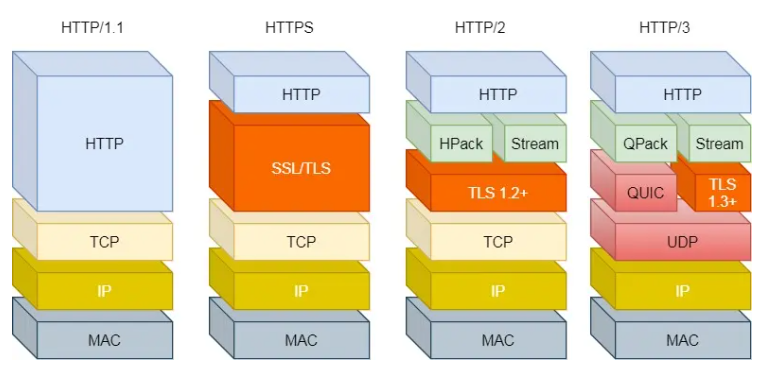
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,但是这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS/1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商,如下图:
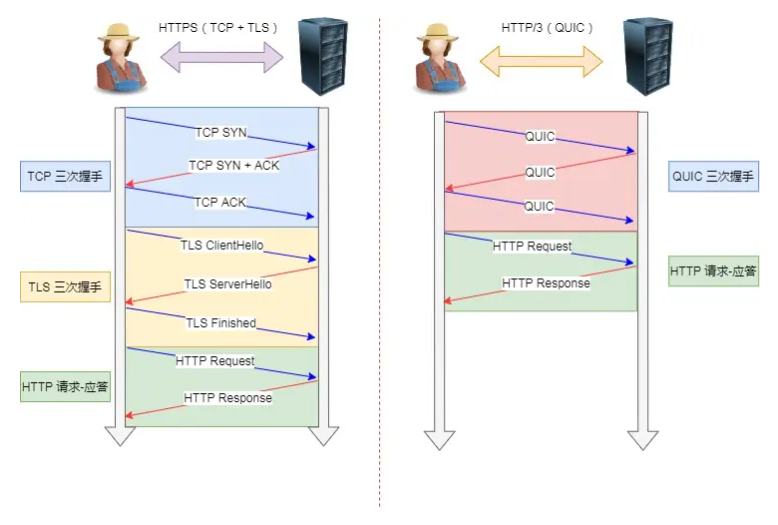
甚至,在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT(下图的右下角):
连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
所以, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题,因为有的网络设备是会丢掉 UDP 包的,而 QUIC 是基于 UDP 实现的,那么如果网络设备无法识别这个是 QUIC 包,那么就会当作 UDP包,然后被丢弃。
HTTP/3 现在普及的进度非常的缓慢,不知道未来 UDP 是否能够逆袭 TCP。